
Fichier trop lourd pour être envoyé par mail ?
Vous avez déjà rencontré ce message d’erreur frustrant : « fichier trop lourd pour être envoyé par mail » ?
Inutile de compresser à l’aveugle, de perdre du temps ou de chercher une solution compliquée. Pour découper proprement un fichier volumineux en plusieurs morceaux, il existe un outil simple, efficace et déjà disponible sous Linux : split.
Pour les utilisateurs de Windows ou d’autres systèmes, pas de panique : l’idée reste la même, et des solutions équivalentes existent. Nous y reviendrons plus loin dans l’article, avec des pistes simples pour adapter la méthode à votre environnement.
Les limites des services de transfert en ligne
On pense souvent aux services de transfert en ligne comme WeTransfer ou équivalents. Ils peuvent dépanner, mais ils reposent généralement sur des liens temporaires. En effet ces liens expirent au bout de quelques jours.
Résultat : un destinataire qui lit son message trop tard peut se retrouver devant un lien inutilisable. Pour un envoi important, une archive à conserver, ou un échange que l’on veut maîtriser, ce n’est pas toujours la solution la plus fiable.
Pourquoi « Split » est la solution ultime (et comment ça marche)
Contrairement à une compression ZIP qui tente de réduire la taille, split se contente de découper votre fichier comme on découperait une tarte (aux pommes 🥧 ) en parts égales.
Mais quel est l’avantage ? Aucune perte de données, aucune corruption possible, et une rapidité d’exécution fulgurante puisque l’ordinateur ne « calcule » rien, il se contente de segmenter.
Exemple dans votre terminal :
split -b 20M gros.zip chapitre_
C’est instantané ! Votre fichier gros.zip a été découpé en plusieurs chapitres.
L’option -b indique à split que le découpage doit se faire selon une taille maximale : ici, chaque morceau pèsera au maximum 20 Mo.
C’est le choix naturel pour une archive ZIP, une vidéo, un PDF volumineux ou tout fichier que l’on veut envoyer en plusieurs parties.
Si l’option -b est absente, split change de logique : il découpe alors le fichier selon un nombre de lignes, avec une valeur par défaut de 1000 lignes par morceau.
On peut d’ailleurs préciser ce nombre avec l’option -l, par exemple :
split -l 500 fichier.txt partie_.
Pour les fichiers CSV, ce découpage par lignes est particulièrement utile : il permet de diviser un gros export en plusieurs fichiers plus faciles à ouvrir, à envoyer ou à retravailler dans un tableur.
Si vous cherchez une solution plus guidée, vous pouvez aussi utiliser mon outil en ligne de découpage CSV : outil en ligne de découpage CSV
Les options -b et -l s’excluent donc naturellement :
- la première découpe selon le poids du fichier,
- la seconde selon le nombre de lignes.
Il faut choisir l’une ou l’autre selon le type de fichier et l’objectif recherché.
Au sujet de suffixes : aa, ab, ac, etc.
1. Les suffixes par défaut : des lettres
Si vous utilisez split sans option, les suffixes sont composés de lettres minuscules, en commençant par aa, ab, ac, etc.
Exemple :
split mon_fichier.txt partie_
Résultat :
partie_aapartie_abpartie_acpartie_ad- …
Explication :
- Le préfixe est
partie_. - Les suffixes commencent par
aaet incrémentent comme un compteur en base 26 (a, b, c, …, z, aa, ab, ac, etc.). - Par défaut, les suffixes ont 2 caractères.
Cas pratique :
Si vous avez 30 morceaux, les suffixes iront de aa à az, puis ba, bb, etc.
2. Les suffixes numériques : plus lisibles avec -d
L’option -d remplace les lettres par des nombres, ce qui rend les noms de fichiers plus intuitifs et plus faciles à trier.
Exemple :
split -d mon_fichier.txt partie_
Résultat :
partie_00partie_01partie_02partie_03- …
Explication :
- Les suffixes sont maintenant des nombres (
00,01,02, etc.). - Cela permet un tri naturel dans l’explorateur de fichiers (contrairement aux lettres, où
aavient avantab, maiszvient aprèsa).
Pourquoi utiliser -d ?
- Plus lisible pour les humains.
- Plus facile à manipuler dans des scripts ou des outils automatisés.
3. Personnaliser la longueur des suffixes avec -a
Par défaut, les suffixes ont 2 caractères (ex: aa, 00). Avec l’option -a, vous pouvez définir le nombre de caractères pour les suffixes.
Exemple avec des lettres :
split -a 3 mon_fichier.txt partie_
Résultat :
partie_aaapartie_aabpartie_aac- …
Explication :
-a 3indique que les suffixes doivent avoir 3 caractères.- Utile si vous avez beaucoup de morceaux (plus de 26² = 676 fichiers avec 2 lettres).
Exemple avec des nombres :
split -d -a 4 mon_fichier.txt partie_
Résultat :
partie_0000partie_0001partie_0002- …
Explication :
-dactive les suffixes numériques.-a 4définit des suffixes à 4 chiffres.- Idéal pour des milliers de fichiers (jusqu’à 9999).
4. Tableau récapitulatif des suffixes
Suffixes générés par split
| Option | Exemple de suffixes | Nombre de caractères | Type de suffixe | Cas d’usage |
|---|---|---|---|---|
| Aucune | aa, ab, ac | 2 | Lettres | Par défaut, pour un petit nombre de fichiers. |
-d | 00, 01, 02 | 2 | Nombres | Pour un tri naturel et une meilleure lisibilité. |
-a 3 | aaa, aab, aac | 3 | Lettres | Pour plus de 676 fichiers. |
-d -a 3 | 000, 001, 002 | 3 | Nombres | Pour plus de 100 fichiers. |
-d -a 4 | 0000, 0001 | 4 | Nombres | Pour plus de 1000 fichiers. |
5. Pourquoi choisir un type de suffixe plutôt qu’un autre ?
- Lettres (
aa,ab, …) :- Avantage : Compact (2 caractères suffisent pour 676 fichiers).
- Inconvénient : Moins intuitif pour trier ou identifier les fichiers.
- Nombres (
00,01, …) :- Avantage : Lisible, tri naturel, facile à manipuler.
- Inconvénient : Nécessite plus de caractères pour un grand nombre de fichiers (ex: 4 chiffres pour 10 000 fichiers).
- Longueur personnalisée (
-a) :- À utiliser si vous avez beaucoup de morceaux (ex: un fichier de 10 Go divisé en morceaux de 1 Mo = 10 000 fichiers).
Et pour ceux qui ne sont pas sous Linux ?
Sous Windows, une solution simple consiste à installer Git for Windows, qui fournit Git Bash.
Ce petit terminal permet d’utiliser de nombreuses commandes issues du monde Unix directement depuis Windows.
On garde son environnement Windows habituel, mais on dispose d’un terminal plus proche de celui utilisé sous Linux.

On recolle avec cat
Découper un fichier n’a d’intérêt que si l’on peut ensuite le reconstituer proprement. Sous Linux, on utilise pour cela la commande cat, qui va lire les morceaux dans l’ordre et les regrouper dans un nouveau fichier.
cat chapitre_* > gros_reconstitue.zip
Dans cet exemple, tous les fichiers dont le nom commence par chapitre_ sont assemblés pour recréer une archive complète. L’ordre des suffixes est donc important :
chapitre_aa,- puis
chapitre_ab, - puis
chapitre_ac, - etc.
Il faut aussi vérifier que tous les morceaux sont présents dans le même dossier avant de lancer la commande.
Une fois le fichier reconstitué, on peut l’ouvrir normalement, comme le fichier d’origine.
Et sous Windows ?
Sous Windows, deux solutions simples existent. On peut utiliser Git Bash, évoqué plus haut, pour retrouver les commandes split et cat dans un terminal proche de Linux. Dans ce cas, la méthode reste quasiment la même que sous Linux : on découpe avec split, puis on recolle avec cat.
Mais on peut aussi utiliser les outils intégrés à Windows, notamment l’invite de commandes, avec la commande copy.
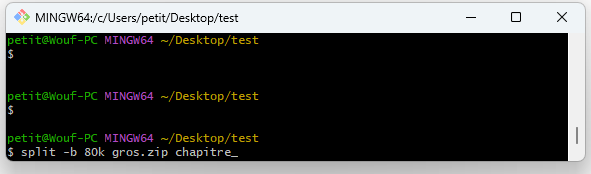
Si le fichier a été découpé par taille, par exemple avec :
split -b 20M gros.zip chapitre_
il faut recoller les morceaux en mode binaire. C’est indispensable pour une archive ZIP, une vidéo, un PDF ou une image, car le contenu ne doit pas être interprété comme du texte.
copy /b chapitre_aa+chapitre_ab+chapitre_ac gros_reconstitue.zip
L’option /b indique à Windows d’assembler les fichiers octet par octet, sans modification. L’ordre des morceaux est essentiel : chapitre_aa, puis chapitre_ab, puis chapitre_ac, etc.
Si le fichier a été découpé par lignes, par exemple avec un fichier .txt ou .csv, on peut aussi utiliser une concaténation plus classique :
copy chapitre_aa+chapitre_ab+chapitre_ac fichier_reconstitue.txt
Mais, par prudence, copy /b reste souvent le choix le plus sûr, même pour recoller un fichier texte. La vraie différence se situe donc surtout dans le découpage : -b sert aux fichiers à reconstituer exactement octet par octet, tandis que -l sert aux fichiers texte découpés proprement ligne par ligne.
Pour aller plus loin : split dans un pipeline
La vraie force de split, comme beaucoup de commandes Unix, apparaît quand on l’intègre dans un pipeline. Il n’est pas toujours nécessaire de créer un fichier intermédiaire avant de le découper : on peut envoyer directement le résultat d’une commande vers split grâce au caractère |.
Avec Grep
grep "France" gros_fichier.csv | split -l 1000 - france_
Ici, on extrait d’abord les lignes contenant France, puis on découpe le résultat en fichiers de 1000 lignes. C’est typiquement l’esprit Unix : une petite commande pour filtrer, une autre pour découper, et l’ensemble produit un outil très efficace.
Documentation officielle et ressources utiles sur la commande split
Pour aller plus loin avec la commande split sous Linux, le mieux reste de consulter des sources fiables. Le manuel officiel GNU Coreutils consacré à split présente en détail les options essentielles, comme -b pour découper un fichier par taille, -l pour découper un fichier par nombre de lignes, ou encore les options liées aux suffixes. La page split(1) sur man7.org constitue aussi une référence claire pour vérifier rapidement la syntaxe d’une commande. Enfin, pour les utilisateurs de Windows qui souhaitent recoller des fichiers découpés, la documentation Microsoft sur la commande copy permet de mieux comprendre l’usage de copy /b en mode binaire.